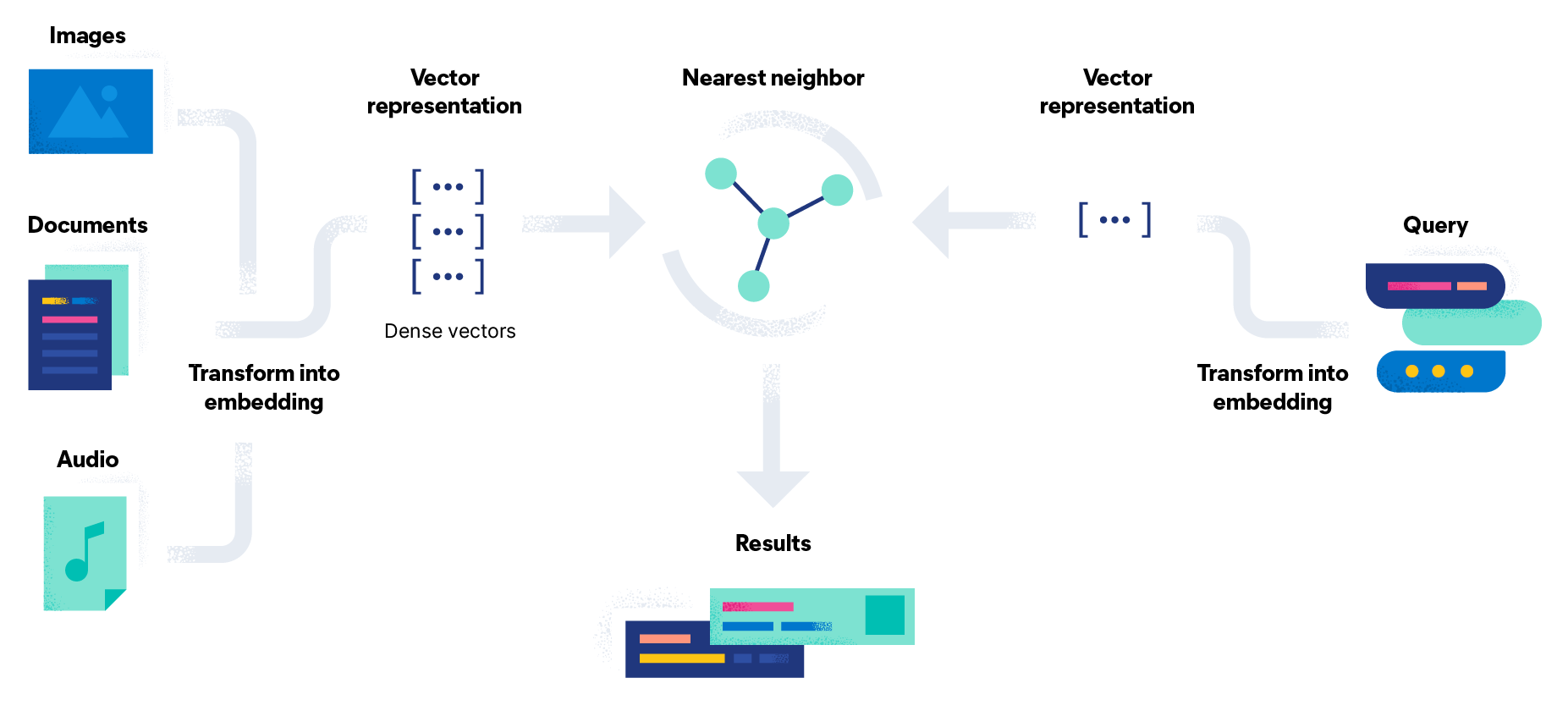
Information retrieval (IR) is a process that facilitates the effective and efficient retrieval of relevant information from large collections of unstructured or semi-structured data. IR systems assist in searching for, locating, and presenting information that matches a user's search query or information need.
As the dominant form of information access, information retrieval is relied upon by billions of people every day who use search engines. Deploying various models, algorithms, and increasingly advanced techniques (think: vector search), information retrieval systems enable search access to a vast and growing array of sources, including documents, items within documents, metadata, and databases of texts, images, videos, and sounds.
The roots of information retrieval can be traced back to ancient times, when libraries and archives were established to organize and store information, including the indexing and alphabetization of scholarly work. By the 1800s, punch cards were being used to process information, and in 1931, Emanuel Goldberg received a patent for the first successful electromechanical document retrieval device, known as the "Statistical Machine," designed for searching through data encoded on film.
Information retrieval began to formalize into what would become a scientific discipline in the mid-20th century, alongside the development of modern computers. Gerard Salton and Hans Peter Luhn pioneered early models for automated document retrieval. Salton and colleagues at Cornell created the SMART Information Retrieval System in the 1960s, a milestone in the field credited with laying the foundation for modern IR techniques and key concepts, including the term-document matrix, the vector space model, relevance feedback, and Rocchio classification.
By the 1970s, with the emergence of more advanced retrieval techniques, probabilistic models, and fully articulated vector processing frameworks, the field had advanced significantly. With the advent of search engines in the late 1990s, IR systems and models that were once mostly the province of academia, institutions, and libraries were put into wide service.
Different types of information retrieval models are designed to tackle specific challenges and establish processes to retrieve relevant information. There are classical models that form the foundations of the field, non-classical models that attempt to address the limitations of traditional approaches, and alternative IR models that go even further, often by integrating advanced technologies like machine learning and language models. On a general level, the most common types of information retrieval models include:
Boolean model
One of the simplest and earliest information retrieval models, the Boolean model is based on Boolean logic, which uses operators including AND, OR, and NOT to combine query terms. Documents are represented as sets of terms, and a query is processed to identify documents that match the specified conditions. Though it’s effective for precise query matches, the Boolean model can't rank documents based on relevance or deliver partial matches.
Vector space model
In this model, documents, and queries are represented as vectors in a multi-dimensional space. Each dimension corresponds to a unique term, and the value in each dimension represents the importance and frequency of the term in the document or query. The cosine similarity between the query vector and document vectors is calculated to determine the relevance of documents to the query. Developed in part to address the disadvantages of the Boolean model, the vector space model can provide ranked results based on relevance scores and is widely used in text retrieval.
Probabilistic model
This model estimates the probability that a document is relevant to a given query. It considers factors like term frequency and document length to calculate relevance probabilities. It is particularly useful for dealing with large amounts of data. Because it works with weighted statistics, the model is an ideal fit for providing ranked results.
Latent semantic indexing (LSI)
LSI uses singular value decomposition (SVD) to capture the semantic relationships between terms and documents. Like semantic search, semantic indexing uses intent and context to identify conceptually related documents even if they don't share exact terms. This key capability makes LSI useful for extracting the contextual meaning of words in a body of text.
Okapi BM25
One of the more popular variants of the probabilistic model, BM25 is a search relevance ranking function. It is used by search engines to estimate the relevance of a document to a search query. It ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the terms within a document, and consists of many scoring functions with different components and parameters. The BM stands for "best matching."
In the Information Age, data is generated every single second at a scale that was once unimaginable. Without a viable means of accessing information, the data is effectively useless. IR systems ensure that users can obtain the relevant information they need amidst the growing noise of information overload.
Information retrieval plays a vital role across nearly every industry and domain in the modern world, from academia and ecommerce to healthcare and defense. It's a human-machine interface that aids in decision-making, research, and knowledge discovery, on both an enterprise and personal level. From searching our localized desktops to discovering the news of the world, or from genomic research to spam filtering, information retrieval is fundamental to nearly every facet of our lives.
Search engines rely on information retrieval models to deliver accurate search results. Ecommerce platforms use retrieval models to recommend products based on user preferences and behavior. Digital libraries rely on information retrieval science to help users do research. In healthcare, IR systems assist in searching databases for relevant patient records, medical research, and treatment protocols. And legal professionals use information retrieval to comb through large volumes of legal cases for precedents.
The information retrieval process is typically triggered when a user enters a formal query into a system stating their information needs. The IR system creates an index of documents in a content collection or information database. Data objects, including those from text documents, images, audio, and videos, are processed to extract relevant terms and surrogate data, and data structures are used to efficiently store and retrieve those entities.
When a user submits a query, the system processes it to identify relevant terms and determine their importance. The system then ranks documents based on their relevance to the query. In many cases, IR models and algorithms are used to calculate a numeric score based on how well each object in the collection or database matches the query. Many queries won’t be an exact match: the most relevant documents are presented to the user in a ranked list. These ranked results represent one of the key differences between information retrieval search and database search.
An information retrieval system consists of several key components:
Document collection
The set of documents that the system can retrieve information from.
Indexing component
Source data and documents are processed to create an index, mapping terms and data to the documents that contain them — often in a dedicated, optimized data structure.
Query processor
The query processor analyzes user queries and keywords and prepares them for matching against the indexed entities.
Ranking algorithm
The ranking algorithm determines the relevance of documents to a query and assigns them scores. The most common is the BM25 (Best Match 25) ranking algorithm, which is notable for its modified approach to term frequency that avoids oversaturating the document with keywords and repeated terms.
User interface
The UI is the display through which users interact with the system, submit queries, and are presented with results. Here, results can be tuned based on how well they serve a user query. In some cases, mechanisms might allow users to provide feedback on the relevance of retrieved documents, which can be used to improve future retrievals.
Significant benefits of information retrieval models include:
Despite significant advancements, information retrieval has never been perfect. Known issues, challenges, and limitations remain, including:
Ambiguity Natural language is inherently ambiguous, making it challenging to accurately interpret user queries. Similar issues of vagueness and uncertainty can affect the indexing and evaluation process, particularly with objects like images and videos.
Relevance Determining relevance is subjective and can vary based on user context and intent. Criteria used to determine worth and significance may be governed by a set of imperfect, general standards that don’t reflect the specific needs of the individual user.
Semantic gaps Retrieval systems can struggle to capture the deeper meaning of content due to the gap between textual representation and human understanding. Lack of clarity in information and user expression represents a major obstacle to successful IR. Advanced natural language processing powered by AI seeks to close those semantic and ambiguity gaps.
Scalability As data volumes increase, maintaining efficient and effective retrieval and indexing becomes more complex, with more and more resources and computing power required.
With recent breakthroughs in generative AI and machine learning, information retrieval as we know it may be on the verge of transformational change.
Advanced machine learning techniques are already enhancing retrieval by learning from user interactions and adapting to changing contexts, locations, and preferences. Improved natural language processing and semantic analysis create a better understanding of user queries and document content. Retrieval systems are also evolving to more effectively handle the ever-growing deluge of multimedia content.
The impact of generative AI on information retrieval has the potential to be revolutionary. Instead of the ranked list of results we’re used to, which requires manually sorting through existing links and documents to find what we’re looking for, we’ll receive actual answers to our questions. The context will be carried over from question to question, allowing for complex, conversational, multi-step inquiries, with the barriers of human language processing and intent all but erased. Rather than piecing together answers ourselves, search engines will do the work for us, synthesizing information into specific, customized results in the form of original content that provides exactly what we need — and nothing we don't.
Deep dive into 2024 technical search trends. Watch this webinar to learn best practices, emerging methodologies, and how the top trends are influencing developers in 2024.
Elastic is dedicated to constantly improving the information retrieval capabilities available in the Elastic Stack. Our newest retrieval model, the Elastic Learned Sparse Encoder, augments Elastic's out-of-the-box retrieval with a pre-trained language model. And to achieve a truly one-click experience, we've integrated it with the new Elasticsearch Relevance Engine.
Elasticsearch also has excellent lexical retrieval capabilities and rich tools for combining the results of different queries, a concept known as hybrid retrieval. We're also enhancing chatbot capabilities with NLP and vector search, releasing third-party natural language processing models for text embeddings, and evaluating our performance using a subset of BEIR.
Whenever you're ready. here are four ways we can help you harness insights from your business' data: